GitHub - lsh2613/spring-spatial-idx: spirng + mysql의 spatial 인덱스 적용
spirng + mysql의 spatial 인덱스 적용. Contribute to lsh2613/spring-spatial-idx development by creating an account on GitHub.
github.com
1. Spatial Index (공간 인덱스 )
공간 데이터(예: 점, 선, 폴리곤 등)와 관련된 효율적인 검색 및 처리를 위해 데이터베이스에서 제공하는 특수한 인덱스.
공간 데이터를 처리하기 위해 설계된 구조로 지도상의 특정 위치를 나타내기 위해 사용되며 위도, 경도와 같은 좌표계를 활용한다.
1.1. MBR
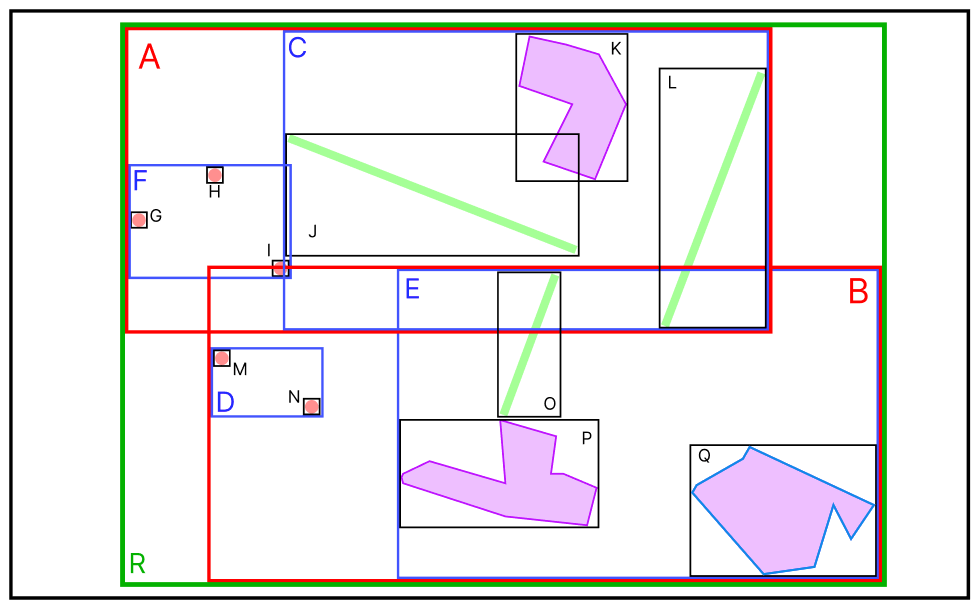
R-Tree는 공간 도형을 MBR(Minimum Bounding Rectangle) 즉, 최소 크기의 사각형으로 만들어 포함관계를 트리 형태로 구현한 것이다
1.2. R+Tree
B-Tree의 확장개념인 R-Tree로 관리되는 인덱스로 1차원의 데이터를 관리하는 B-Tree와 달리 R-Tree는 다차원의 데이터를 관리한다.
공간 데이터가 MBR로 변환되고 MBR의 포함 관계를 바탕으로 R-Tree 트리가 만들어진다
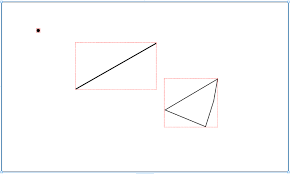
1. 공간 데이터 추출
2. 공간 데이터를 MBR로 변환
3. MBR의 포함 관계를 통해 R-Tree 구성
2. MySQL의 Spatial Index
MySQL에서는 공간 인덱스를 위해 공간 확장 기능을 제공한다
2.1. MySQL의 공간 데이터 타입
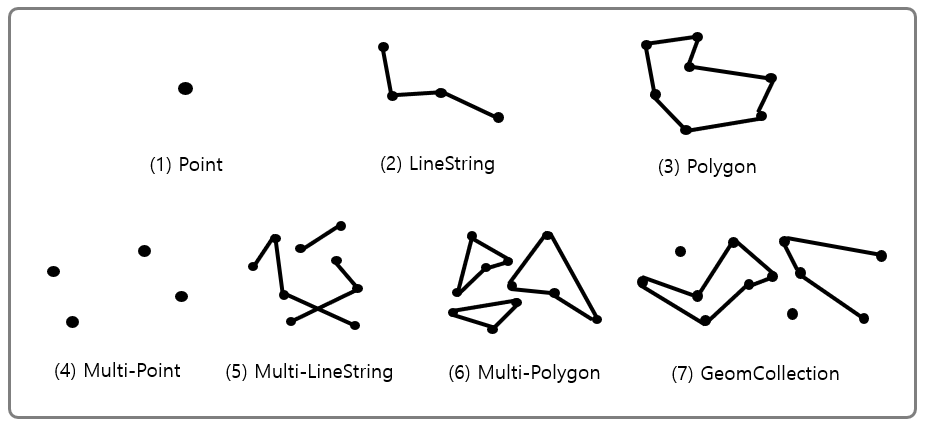
- 위 공간 데이터 타입의 슈퍼 타입은 Geometry 타입이 존재한다
2.2. MySQL의 공간 데이터 함수
| 함수명 | 설명 |
| ST_GeomFromText(WKT*[, SRID]*) | WKT와 SRID를 통해 geometry를 생성한다 |
| ST_Buffer((Multi) Point, Radius) | Point(또는 MultiPoint)로 부터 Radius를 반지름으로 갖는 원을 그린다 |
| ST_Contains(geom(a), geom(b)) | 가 a에 포함되어 있으면 1을 반환, 아니면 0을 반환 |
| ST_Within(geom(a), geom(b)) | a가 b에 포함되어 있으면 1을 반환, 아니면 0을 반환 (ST_contains와 인자가 반대) |
| ST_Distance(geom(a), geom(b)) | a와 b 사이의 거리 |
WKT
Well Known Text로, 공간 데이터를 텍스트 형식으로 표현하는 방법
2.3. Spatial Index 생성
CREATE SPATIAL INDEX [인덱스 명] ON [테이블 명](컬럼 명);
3. Spring + MySQL의 Spatial Index 적용
공간 인덱스를 사용하기 전에 MySQL에서 지원하는 공간 데이터 처리를 먼저 적용해 보자.
JPA에서 공간 데이터를 처리하기 위해 hibernate-spatial docs를 참고할 수 있다.
hibernate-spatial은 JTS, geolatte-geom라는 두 geometry model을 지원하는데 이 포스팅에서는 JTS를 활용한다
3.1 공간 데이터 생성
build.gradle
// hibernate-spatial
implementation group: 'org.hibernate', name: 'hibernate-spatial', version: '6.2.5.Final'
앞으로 나오는 공간 데이터 관련 기능들은 org.locationtech.jts 라이브러리를 활용한다
먼저 공간 데이터를 생성하기 위해 GeometryFactory, WKTReader를 활용할 수 있다
그 중 Point를 생성하여 테스트 해보았다
@Test
void createPointWithFactory() {
//given
GeometryFactory geometryFactory = new GeometryFactory();
Coordinate coordinate = new Coordinate(180, 90);
//when
Point point = geometryFactory.createPoint(coordinate);
point.setSRID(4326);
//then
assertThat(point.getX()).isEqualTo(180);
assertThat(point.getY()).isEqualTo(90);
}
@Test
void createPointWithWKT() throws ParseException {
//given
WKTReader wktReader = new WKTReader();
//when
Point point = (Point) wktReader.read("POINT(180 90)");
point.setSRID(4326);
//then
assertThat(point.getX()).isEqualTo(180);
assertThat(point.getY()).isEqualTo(90);
}
사실 WKTReader도 내부에 GeometryFactory를 가지고 있어 문자열을 파싱해서 처리해주는 것뿐이다
public class WKTReader {
...
private GeometryFactory geometryFactory;
public WKTReader() {
this(new GeometryFactory());
}
...
}
3.2 공간 인덱스 적용
이제 본격적으로 공간인덱스를 활용하기 위한 엔티티를 만들어 보자
테스트를 하기 위해 Point 공간 타입의 좌표를 가지는 엔티티를 만들어주었다.
MyCoordinate
@Getter
@Entity
@NoArgsConstructor
public class MyCoordinate {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private Point point;
private MyCoordinate(Point point) {
this.point = point;
}
static public MyCoordinate createPointWithSRID4326(Point point) {
point.setSRID(4326);
return new MyCoordinate(point);
}
}공간 데이터 타입에 대해 SRID를 꼭 설정해주어야 한다
Point 컬럼은 org.locationtech.jts.geom 라이브러리를 사용해야 한다
공간 인덱스가 될 컬럼은 not-null 제약이 존재해야 하기 때문에 nullable=false를 넣어준다
SRID란
Spatial Refence Identifier로 좌표계를 구분하는 식별자이다.
가장 흔히 사용하고 대중적인 좌표계는 위도, 경도를 사용하는 지구 기준 좌표계로 WGS84(GPS)이고 이 좌표계의 식별코드가 4326이다
이제 MyCoordinate의 point 컬럼에 공간 인덱스를 설정해야 한다. 또한 공간인덱스를 설정하는 컬럼에 SRID 값을 추가해줘야 한다.
매번 프로젝트 띄우고 db에 공간 인덱스 생성 쿼리를 추가하기 번거로우므로 schema.sql을 활용하였다
schema.sql
ALTER TABLE my_coordinate MODIFY COLUMN point POINT NOT NULL SRID 4326;
CREATE SPATIAL INDEX spatial_idx ON my_coordinate (point);
그대로 실행하면 hibernate 테이블 초기화 전에 schema.sql이 먼저 실행되기 때문에 테이블이 생성되지 않았다는 에러가 발생할 것이다.
schema.sql 파일이 hibernate 테이블 초기화 이후 동작하게 하기 위해 defer-datasource-initialization: true 옵션을 추가해줘야 한다.
spring:
jpa:
hibernate:
ddl-auto: create
show-sql: true
properties:
hibernate.format_sql: true
hibernate.dialect: org.hibernate.dialect.MySQL8Dialect
defer-datasource-initialization: true
sql:
init:
mode: always
이제 공간 인덱스를 사용하기 위한 시나리오를 만들어 줘야 한다.
먼저 공간 인덱스도 말 그대로 인덱스다. 따라서 인덱스가 활용되는 조건은 세컨더리 인덱스와 동일하다. 옵티마이저가 여러 환경, 조건, 비용에 따라 인덱스 스캔, 풀 스캔 중 더 효율적인 것을 계산하기 때문에 조건이 다소 추상적일 수밖에 없다.
인덱스 활용 조건
1. 테이블의 데이터 개수가 적지 않아야 함
2. 조회하는 데이터의 비율이 너무 많지 않아야 함
3. 추가 조건 등등 ..
위 조건과 더불어 공간 인덱스를 활용하기 위해선 포함 관계 비교를 사용해야 한다.
R-Tree는 MBR의 포함 관계를 이용해 만들어진 인덱스이기 때문에 거리 비교 함수(ST_Distance(), ST_Distance_Sphere())가 아닌 포함 관계 비교 (ST_Contains(), ST_Within()) 시 인덱스가 사용된다
먼저 포함 관계 비교가 들어간 쿼리문을 작성해보자
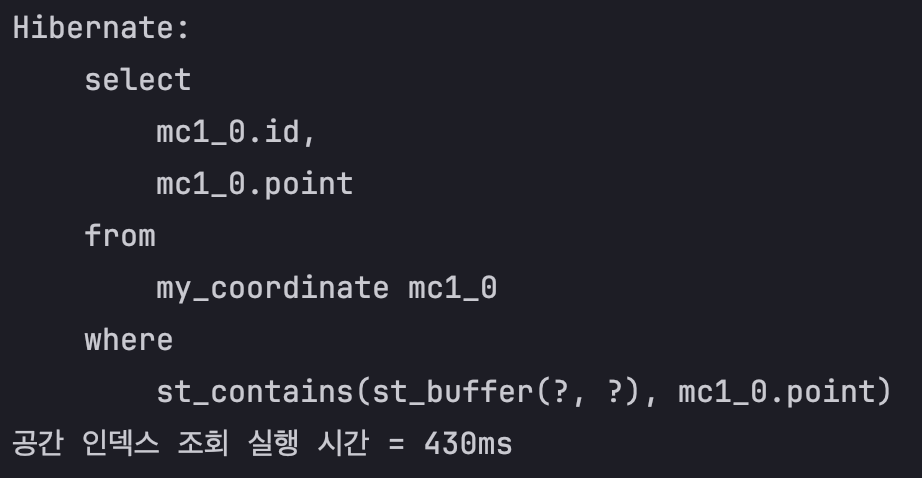
MyCoordinateRepository
@Repository
public interface MyCoordinateRepository extends JpaRepository<MyCoordinate, Long> {
@Query("""
SELECT co
FROM MyCoordinate AS co
WHERE st_contains(st_buffer(:center, :radius), co.point)
""")
List<MyCoordinate> findAllWithInCircleAreaWithIdx(@Param("center") final Point center,
@Param("radius") final int radius);
@Query(value = """
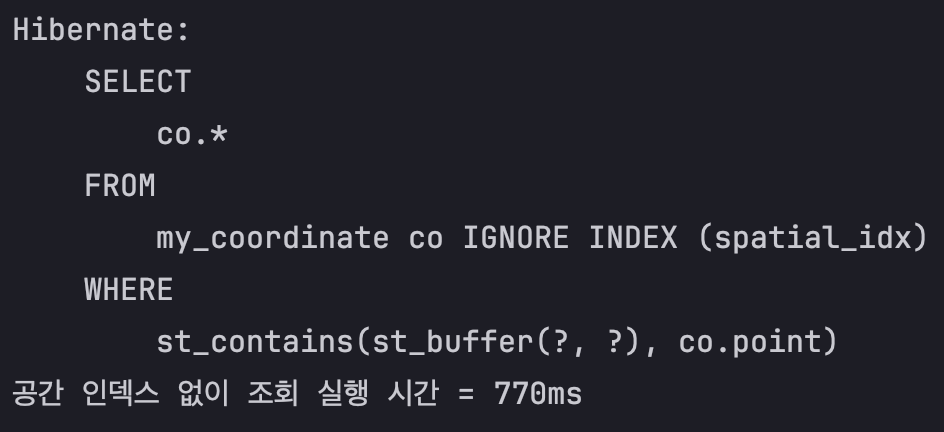
SELECT co.*
FROM my_coordinate co IGNORE INDEX (spatial_idx)
WHERE st_contains(st_buffer(:center, :radius), co.point)
""", nativeQuery = true)
List<MyCoordinate> findAllWithInCircleAreaWithoutIdx(@Param("center") final Point center,
@Param("radius") final int radius);
}특정 지점을 기준으로 반지름이 radius인 원을 그렸을 때 해당 원 안에 존재하는 데이터를 조회한다.
즉, 반경 radius m 내의 데이터를 조회하는 쿼리이다
공간 인덱스를 사용하지 않는 쿼리와 성능 분석을 위해 두 쿼리를 작성
다음은 테스트를 하기 위한 데이터를 만들어야 한다.
총 10,000개의 데이터 중 200개는 Point(0 0)에서 반경 5000m 이내의 Point를 만들어서 저장했고, 나머지는 9,800개는 반대로 반경 밖의 Point를 만들어 저장했다.
@Autowired
private MyCoordinateRepository repository;
private static final GeometryFactory geometryFactory = new GeometryFactory();
private static final int QUERY_HIT = 200;
@BeforeAll
static void setupData(@Autowired JdbcTemplate jdbcTemplate) {
// 중심 좌표 (0, 0)에서 반경 5000m 내에 포함될 좌표 QUERY_HIT개 생성
List<MyCoordinate> myCoordinates = new ArrayList<>();
for (int i = 0; i < QUERY_HIT; i++) {
Point point = geometryFactory.createPoint(new Coordinate(
Math.random() * 0.01 - 0.005, // -0.005 ~ 0.005 범위의 위도
Math.random() * 0.01 - 0.005 // -0.005 ~ 0.005 범위의 경도
));
myCoordinates.add(MyCoordinate.createMyCoordinateWithSRID4326(point));
}
// 중심 좌표 (0, 0)에서 반경 5000m 내에 포함되지 않는 좌표 나머지 생성
for (int i = 0; i < 10000 - QUERY_HIT; i++) {
Point point = geometryFactory.createPoint(new Coordinate(
Math.random() * 180 - 90, // 임의의 위도 (-90 ~ 90)
Math.random() * 180 - 90 // 임의의 경도 (-180 ~ 180)
));
myCoordinates.add(MyCoordinate.createMyCoordinateWithSRID4326(point));
}
batchInsertCoordinates(jdbcTemplate, myCoordinates);
}
private static void batchInsertCoordinates(JdbcTemplate jdbcTemplate, List<MyCoordinate> coordinates) {
String sql = "INSERT INTO my_coordinate (point) VALUES (ST_PointFromText(?, 4326))";
List<Object[]> batchArgs = new ArrayList<>();
for (MyCoordinate coordinate : coordinates) {
batchArgs.add(new Object[] { coordinate.getPoint().toText() });
}
jdbcTemplate.batchUpdate(sql, batchArgs);
}
Point(0 0)에서 반경 5000m 이내의 데이터 200개가 조회되는지 테스트해 보자.
@Test
void 공간_인덱스_조회() {
//given
Point center = geometryFactory.createPoint(new Coordinate(0, 0));
center.setSRID(4326);
int radius = 5000;
//when
long start = System.currentTimeMillis();
List<MyCoordinate> results = repository.findAllWithInCircleAreaWithIdx(center, radius);
long end = System.currentTimeMillis();
System.out.println("공간 인덱스 조회 실행 시간 = " + (end-start));
//then
assertThat(results.size()).isGreaterThanOrEqualTo(QUERY_HIT);
}
@Test
void 공간_인덱스_없이_조회() {
//given
Point center = geometryFactory.createPoint(new Coordinate(0, 0));
center.setSRID(4326);
int radius = 5000;
//when
long start = System.currentTimeMillis();
List<MyCoordinate> results = repository.findAllWithInCircleAreaWithoutIdx(center, radius);
long end = System.currentTimeMillis();
System.out.println("공간 인덱스 없이 조회 실행 시간 = " + (end-start));
//then
assertThat(results.size()).isGreaterThanOrEqualTo(QUERY_HIT);
}
위에서 사용한 똑같은 쿼리를 explain으로 공간 인덱스가 타는 지를 확인해 볼 수 있다
# 공간 인덱스 X
EXPLAIN
SELECT co.*
FROM my_coordinate co IGNORE INDEX (spatial_idx)
WHERE ST_Contains(ST_Buffer(ST_GeomFromText('POINT(0 0)', 4326), 5000), co.point);
# 공간 인덱스 O
EXPLAIN
SELECT co.*
FROM my_coordinate co
WHERE ST_Contains(ST_Buffer(ST_GeomFromText('POINT(0 0)', 4326), 5000), co.point);

4. 공간 인덱스 성능 비교
이 테스트는 총 10,000 개의 데이터 중 특정 Point 기준으로 반경 5000m 이내의 200개의 Point를 공간 인덱스를 통한 조회와, 공간 인덱스를 타지 않은 조회를 비교한다
먼저 애플리케이션 레벨에서의 테스트이다.
두 테스트 쿼리 모두 똑같은 데이터를 조회하기 때문에 이미 조회된 데이터가 버퍼풀에 저장되어 캐싱된다. 따라서, 두 메소드를 같이 실행하면 먼저 실행된 쿼리보다 늦게 실행된 쿼리가 무조건 실행시간이 짧게 나온다.
정상적으로 실행시간을 비교하기 위해선 각각 따로 실행해주어야 한다.
결과는 공간 인덱스를 타고 조회했을 때 대략 1.79배 빠르다.
다음은 MySQL의 프로파일링 기법을 통해 성능을 측정해보았다.
결과는 공간 인덱스를 타고 조회했을 때 대략 22배 빠르다.

5. 공간 인덱스를 타지 않을 때 살펴볼 점
5.1. 공간 인덱스를 설정한 컬럼의 SRID 속성이 명시적으로 정의됐는지 확인
- Java 레벨에서 Point의 SRID를 설정해놨다 하더라도 MySQL 테이블에서 SRID 설정이 되어 있어야 한다
- 본문 schema.sql 참고
5.2. ST함수에서 쓰이는 공간 데이터에 대해 모두 SRID를 설정했는지 확인
- 조회되는 MyCoordinate.point가 SRID=4326로 되어 있어야 하고
- 조회의 기준이 되는 공간 데이터도 SRID=4326이어야 한다
- 본문 @Test void testFindAllWithInCircleArea() 메소드 참고
5.3. 인덱스를 타기 위한 조건을 확인
- 조건이 너무 많지만 여기서 언급한 조건만 만족해도 된다
- 본문 인덱스 활용 조건 참고
위 조건은 MySQL-Spatial Index docs를 참고하였다
6. 공간 인덱스 사용 시 주의사항
1. 구현 시 사용하는 라이브러리는 org.locationtech.jts.geom이다
2. new Coordinate(x, y)의 인자는 위도, 경도 순서이다
6.1. new Coordinate(x, y)를 통한 조회
주의사항 2번에도 써놨지만 저 말이 참 애매해서 자세히 정리해보려 한다.
[ 단어 정리 ]
x = LonGitude, 경도
y = Latitue, 위도
Coordinate에서는 x, y좌표를 받게되어 있다.
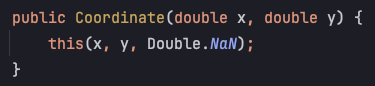
그대로 x, y라 생각하고 new GeometryFactory().createPoint(new Coordinate(128.7064172 35.8426182)); 를 통해 데이터를 삽입하고 조회해보았다

MySQL 상에서 Point는 (위도 경도) 순서 즉, (y x)로 들어가있다. 아마 JPA가 쿼리로 변환하기 위해 Point를 문자열로 변환하는 과정에서 순서가 바뀌는 것 같다. 왜 이렇게 만들었는지 도저히 모르겠다..
그래서 이게 왜 문제냐?
Point의 반경을 조회하기 위해서 st_contains()를 사용하는데, 이 함수는 위도(y)의 범위가 -90 ~ +90이어야만 하기 때문에 크기가 90이 넘어가는 경도(x)때문에 순서가 매우 중요하다. 만약 JPA를 사용한다면 정확한 범위의 경도(x), 위도(y)를 넣어줬다면 알아서 변환해주기 때문에 다음처럼 비교적 의미가 명확하게(?) 작성할 수 있다.
@Query("""
SELECT co
FROM MyCoordinate AS co
WHERE st_contains(st_buffer(:center, :radius), co.point)
""")
List<MyCoordinate> findAllWithInCircleAreaWithIdx(@Param("center") final Point center,
@Param("radius") final int radius);
하지만 동적쿼리가 필요해져서 QuerDSL을 도입하여 생쿼리(?)를 날린다고 가정해보면 다음과 같은 코드가 필요할 것이다
public List<ApartmentRent> searchFilteredApartmentRent(ApartmentRentFilterSearchCond cond) {
return queryFactory
.selectFrom(apartmentRent)
.where(
isWithinRadius(cond.getCenter(), cond.getRadius()),
...
)
.fetch();
}
private BooleanExpression isWithinRadius(Point center, double radius) {
String sql = String.format(
"ST_Contains(ST_Buffer(ST_GeomFromText('%s', 4326), %s), %s)",
center, radius, apartmentRent.point
);
return Expressions.booleanTemplate(sql);
}
...
하지만 center 다음과 같이 생성되었을 때
Point center = new GeometryFactory().createPoint(new Coordinate(128.6460, 35.8580));
반환하는 문자열은 POINT (128.6460 35.8580)일 것이다. (toString()이 x,y 순으로 출력하도록 되어있다)
따라서 MySQL에서는 위도(y)가 128.6460로 90의 범위가 초과되어 에러가 발생하게 된다
Caused by: com.mysql.cj.jdbc.exceptions.MysqlDataTruncation: Data truncation: Latitude 128.646000 is out of range in function st_geomfromtext. It must be within [-90.000000, 90.000000].
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:104)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:916)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeQuery(ClientPreparedStatement.java:972)
at com.zaxxer.hikari.pool.ProxyPreparedStatement.executeQuery(ProxyPreparedStatement.java:52)
at com.zaxxer.hikari.pool.HikariProxyPreparedStatement.executeQuery(HikariProxyPreparedStatement.java)
at org.hibernate.sql.results.jdbc.internal.DeferredResultSetAccess.executeQuery(DeferredResultSetAccess.java:239)
... 101 more
해결법은 간단하다
x, y값을 바꿔서 쿼리를 만들어주면 된다.
private BooleanExpression isWithinRadius(Point center, double radius) {
String sql = String.format(
"ST_Contains(ST_Buffer(ST_GeomFromText('Point (%s %s)', 4326), %s), %s)",
center.getY(), center.getX(), radius, apartmentRent.point
);
return Expressions.booleanTemplate(sql);
}Pont.toString()은 Point (x, y)을 만들어준다. 따라서 getX(), getY()를 사용하려면 'Point (%s %s)' 를 직접 만들어줘야 한다