1. 개요
공유 자원에 대한 동시성 이슈를 해결하기 위한 방법은 다양하다.
그 중에서 낙관적 락, 비관적 락, 분산락에 대해 알아보고 직접 적용해보며 성능 차이를 확인해보려 한다
2. 낙관적 락 (Optimistic Lock)
특징
- 충돌이 발생하지 않는다고 가정
- DB가 제공하는 락 기능이 아닌, 애플리케이션에서 제공하는 버전 관리 기능
- Version이라고 하는 구분 컬럼을 활용
- 트랜잭션 커밋 시점에 충돌을 파악
- 레코드를 업데이트 하는 과정에서만 락을 점유하기 때문에 성능이 좋음
동작
- 공유 자원을 포함하는 ROW에 업데이트 할 때 Version을 증가
- ROW 업데이트 시점에 해당 ROW를 읽었을 때 Version과, 업데이트 시점에 Version이 다르면 예외를 발생
- 같은 경우에만 업데이트 실행
3. 비관적 락 (Pessimistic Lock)
특징
- 충돌이 발생한다고 가정
- Repeatable Read, Serializable 정도의 경리성에서 가능
- 트랜잭션 시작 시 S Lock, X Lock을 건다
- DB가 제공하는 락
- 데이터 수정 즉시 트랜잭션 충돌을 알 수 있다
단점
- DB에 락을 걸어 관리하기 때문에 멀티 DB 환경에서는 동기화 과정이 필요하다
- 데드락이 발생할 수 있다
4. 낙관적 락 vs 비관적 락
4.1. 트랜잭션
낙관적 락은 트랜잭션이 필요하지 않다
- 클라이언트가 서버에 정보 요청
- 서버에서 정보 반환
- 클라이언트에서 이 정보를 이용하여 수정 요청
- 서버에서 수정 적용
위 동작 과정을 살펴보자
낙관적 락은 4번에서 DB에 락을 걸지 않고 애플리케이션에서 Version을 체크하여 충돌을 감지하기 때문에 트랜잭션을 필요로 하지 않는다.
하지만, 비관적 락은 해당 ROW에 2번에서 S-Lock이 걸리고, 3번에서 X-Lock이 걸리기 때문에 Lock을 유지하기 위해 트랜잭션이 계속 유지되어야 한다.
4.2. 성능
위 트랜잭션 내용으로 알 수 있듯이, 비관적 락은 충돌이 일어날 것을 가정하고 해당 ROW에 Lock을 걸어둔다.
따라서, Lock이 걸린 ROW는 읽기 조차 하지 못하고 대기하기 때문에, 대부분의 상황에서 낙관적 락보다 성능이 좋지 않다
하지만 비관적 락이 더 좋은 경우도 있다.
- 재고가 1개인 상품이 있다
- 100만 사용자가 동시적으로 주문을 요청한다
이 경우 비관적 락은 1명의 사용자 말고는 대기를 하다가 미리 트랜잭셩 충돌 여부를 파악한다.
즉, 재고가 없음을 미리 알고 비즈니스 로직을 처리하지 않는다는 의미이다
반대로 낙관적 락은 100만 사용자의 요청을 모두 처리하고, 커밋(업데이트) 시점에 재고가 없음을 파악하게 된다.
그만큼 롤백 처리도 해야 하기 때문에, 자원 소모도 크게 발생하게 된다
즉, 낙관적 락은 충돌이 많이 일어나지 않을 것이라고 예상되는 곳에서 좋은 성능을 기대할 수 있다
4.3 롤백
비관적 락은 트랜잭션을 롤백하면 돼서 DB를 통해 비교적 간단하게 처리할 수 있다
하지만, 낙관적 락은 애플리케이션에서 처리하기 떄문에 충돌이 발생하면 개발자가 수동으로 롤백 처리를 해줘야 한다는 단점이 있다
5. 분산락
낙관적 락은 실패 시 예외처리 + 재시도로 인한 성능 저하
비관적 락은 ROW 자체에 락으로 인한 성능 저하
라는 단점이 존재한다.
분산락은 DBMS에 의존하지 않고 멀티 서버 환경에서 공유된 리소스(Redis, Zookeeper)를 이용해 락을 관리한다
즉, DB 커넥션을 잡은 상태로 트랜잭션 레벨에서 대기하는 비관적 락과 달리 경쟁 로직을 다른 리소스에서 처리하기 때문에 성능적으로 더 좋다.
또한, 별도의 인프라(Redis, Zookeeper)에서 락을 관리하기 때문에 멀티 DB 환경에서도 동시성 이슈를 해결할 수 있다
DB 데이터를 얻기 위해 락을 통해 경쟁을 하는데, 이 락을 얻기 위해 또 경쟁을 하는 것은 매우 비효율적이고 데드락을 발생시킬 수 있다.
Redis 같은 경우 싱글 스레드로 작동하기 때문에 락을 획득하기 위한 경쟁 없이 순차적으로 실행된다. 따라서 데드락 발생 가능성이 없다.
특징
- DB에 직접 락을 걸지 않기 때문에 성능 향상
- 멀티 서버 환경에서도 동시성 제어 가능
- 데드락 발생 가능성 X
6. 구현
Ticket 엔티티를 만들어 quantity(수량) 관리하고, 동시에 티케팅이 이루어졌을 때 원하는 수량만큼 감소하는 테스트를 진행해볼 예정이다
먼저 낙관적 락이다.
낙관적 락
OptimisticTicket
@Getter
@Entity
@NoArgsConstructor
@ToString
public class OptimisticTicket {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long quantity;
@Version
private Long version;
public OptimisticTicket(Long quantity) {
this.quantity = quantity;
}
public static OptimisticTicket create(Long quantity) {
return new OptimisticTicket(quantity);
}
public void decrease(Long quantity) {
long q = this.quantity - quantity;
this.quantity = q < 0 ? 0L : q;
}
}
OptimisticTicketRepository
@Repository
public interface OptimisticTicketRepository extends JpaRepository<OptimisticTicket, Long> {
@Lock(LockModeType.OPTIMISTIC)
@Query("SELECT t FROM OptimisticTicket t WHERE t.id = :id")
OptimisticTicket findByIdWithOptimisticLock(@Param("id") Long id);
}@Lock(LockModeType.OPTIMISTIC)를 적용하면 엔티티를 수정 시 해당 엔티티의 Version을 체크하여 동시성 문제를 해결한다
OptimisticTicketService
@Slf4j
@RequiredArgsConstructor
@Service
public class OptimisticTicketService {
private final TransactionalOptimisticTicketService transactionalService;
public void ticketing(Long ticketId, Long quantity) {
while (true) {
try {
transactionalService.ticketing(ticketId, quantity);
break;
} catch (ObjectOptimisticLockingFailureException e) {
log.info("티케팅에 실패했습니다. 다시 시도합니다.");
try {
Thread.sleep(1000);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw new RuntimeException(ex);
}
}
}
}
}
TransactionalOptimisticTicketService
@RequiredArgsConstructor
@Service
public class TransactionalOptimisticTicketService {
private final OptimisticTicketRepository optimisticTicketRepository;
@Transactional
public void ticketing(Long ticketId, Long quantity) {
OptimisticTicket optimisticTicket = optimisticTicketRepository.findByIdWithOptimisticLock(ticketId);
optimisticTicket.decrease(quantity);
}
}
OptimisticTicketServiceTest
@Slf4j
@SpringBootTest
class OptimisticTicketServiceTest {
@Autowired
private OptimisticTicketService optimisticTicketService;
@Autowired
private OptimisticTicketRepository optimisticTicketRepository;
private final static Integer CONCURRENT_COUNT = 100;
private static Long TICKET_ID = null;
@BeforeEach
public void before() {
log.info("1000개의 티켓 생성");
OptimisticTicket optimisticTicket = OptimisticTicket.create(1000L);
OptimisticTicket saved = optimisticTicketRepository.saveAndFlush(optimisticTicket);
TICKET_ID = saved.getId();
}
@AfterEach
public void after() {
optimisticTicketRepository.deleteAll();
}
private void ticketingTest(Consumer<Void> action) throws InterruptedException {
Long originQuantity = optimisticTicketRepository.findById(TICKET_ID).orElseThrow().getQuantity();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.submit(() -> {
try {
action.accept(null);
} finally {
latch.countDown();
}
});
}
latch.await();
OptimisticTicket optimisticTicket = optimisticTicketRepository.findById(TICKET_ID).orElseThrow();
assertEquals(originQuantity - CONCURRENT_COUNT, optimisticTicket.getQuantity());
}
@Test
@DisplayName("동시에 100명의 티켓팅 : 낙관적 락")
public void redissonTicketingTest() throws Exception {
StopWatch stopWatch = new StopWatch("동시에 100명의 티켓팅 : 낙관적 락");
stopWatch.start();
ticketingTest((_no) -> optimisticTicketService.ticketing(TICKET_ID, 1L));
stopWatch.stop();
log.info(stopWatch.prettyPrint());
}
}
낙관적 락 조회 쿼리를 따로 분리한 이유
OptimisticService에서 직접 트랜잭션을 걸고 optimisticTicketRepository.findByIdWithOptimisticLock()를 통해 엔티티를 조회하도 되지만, 일부러 이를 분리했다.
이를 분리한 이유는 낙관적 락의 동작 과정을 이해하면 쉽게 납득할 수 있다.
낙관적 락은 조회했을 때의 version과 업데이트 시점의 version이 같은지 체크하여 동시성을 해결한다. 만약 version이 같다면 업데이트 시점에 문제가 없다는 뜻이고, version이 다르다면 내가 수정한 사이에 다른 스레드에서 해당 공유 자원에 대한 수정이 있어서 문제가 발생한다는 뜻이다.
만약 동시성 문제가 발생한다면, 예외 처리를 통해 재시도를 시도하도록 구현해뒀다. 이 과정에서 OptimisticTicket을 조회하는 메소드가 같은 트랜잭션에서 실행된다면 쿼리를 날려서 가져오는 것이 아닌 영속성 컨텍스트에 캐싱된 데이터를 가져오기 때문에 계속해서 Old Version을 가져오기 때문에 무한히 락 획득에 실패할 것이다.
따라서 트랜잭션을 분리하여 락 획득에 실패 시 새로 조회할 수 있도록 구현해야 했다.
비관적 락
비교적 간단하다. db에서 조회하여 사용할 때 X-Lock을 걸어 다른 트랜잭션에서 조회할 수 없게 만들어주면 끝이다
Ticket
public interface Ticket {
Long getId();
Long getQuantity();
void setQuantity(Long quantity);
default void decrease(Long quantity) {
long q = getQuantity() - quantity;
setQuantity(q < 0 ? 0L : q);
}
}
PessimisticTicket
@Setter
@Getter
@Entity
@NoArgsConstructor
@ToString
public class PessimisticTicket implements Ticket {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long quantity;
public PessimisticTicket(Long quantity) {
this.quantity = quantity;
}
}
PessimisticTicketRepository
public interface PessimisticTicketRepository extends JpaRepository<PessimisticTicket, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT t FROM PessimisticTicket t WHERE t.id = :id")
PessimisticTicket findByIdWithPessimisticLock(Long id);
}PESSIMISTIC_WRITE를 통해 ROW를 조회할 때 X-LOCK을 건다
PessimisticTicketService
@RequiredArgsConstructor
@Service
public class PessimisticTicketService {
private final PessimisticTicketRepository pessimisticTicketRepository;
@Transactional
public void ticketing(Long ticketId, Long quantity) {
PessimisticTicket pessimisticTicket = pessimisticTicketRepository.findByIdWithPessimisticLock(ticketId);
pessimisticTicket.decrease(quantity);
pessimisticTicketRepository.saveAndFlush(pessimisticTicket);
}
}
PessimisticTicketServiceTest
@Slf4j
@SpringBootTest
class pessimisticTicketServiceTest {
@Autowired
private PessimisticTicketService pessimisticTicketService;
@Autowired
private PessimisticTicketRepository pessimisticTicketRepository;
private final static Integer CONCURRENT_COUNT = 100;
private static Long TICKET_ID = null;
private final static StopWatch stopwatch = new StopWatch();
@BeforeEach
public void before() {
log.info("1000개의 티켓 생성");
PessimisticTicket optimisticTicket = new PessimisticTicket(1000L);
PessimisticTicket saved = pessimisticTicketRepository.saveAndFlush(optimisticTicket);
TICKET_ID = saved.getId();
}
@AfterEach
public void after() {
pessimisticTicketRepository.deleteAll();
}
private void ticketingTest(Consumer<Void> action) throws InterruptedException {
Long originQuantity = pessimisticTicketRepository.findById(TICKET_ID).orElseThrow().getQuantity();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.submit(() -> {
try {
action.accept(null);
} finally {
latch.countDown();
}
});
}
latch.await();
PessimisticTicket optimisticTicket = pessimisticTicketRepository.findById(TICKET_ID).orElseThrow();
assertEquals(originQuantity - CONCURRENT_COUNT, optimisticTicket.getQuantity());
}
@Test
@DisplayName("동시에 100명의 티켓팅 : 비관적 락")
public void redissonTicketingTest() throws Exception {
stopwatch.start("동시에 100명의 티켓팅 : 비관적 락");
ticketingTest((_no) -> pessimisticTicketService.ticketing(TICKET_ID, 1L));
stopwatch.stop();
System.out.println(stopwatch.prettyPrint());
}
}
테스트 결과

분산락
분산락을 적용하기 위해 Redis-Redisson을 활용하였다
Redis-Lettuce은 setnx, setex 등을 활용하여 retry, timeout 같은 기느을 구현해줘야 하는 번거로움이 있다.
Redisson을 선택한 이유는 Lock interface를 지원하기 때문에 락에 대해 타임아웃 같은 설정을 지원하기에 보다 안전하게 사용할 수 있기 때문이다.
build.gradle
// Redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
// Redisson
implementation 'org.redisson:redisson-spring-boot-starter:3.27.0'
RedissonConfig
@Configuration
public class RedissonConfig {
private static final String REDISSON_HOST_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress(REDISSON_HOST_PREFIX + "localhost:6379");
return Redisson.create(config);
}
}
localhost:6379는 현재 띄워둔 redis 환경에 맞춰 설정해주면 된다
DistributedTicket
@Setter
@Getter
@Entity
@NoArgsConstructor
public class DistributedTicket implements Ticket {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long quantity;
public DistributedTicket(Long quantity) {
this.quantity = quantity;
}
}
DistributedTicketRepository
public interface DistributedTicketRepository extends JpaRepository<DistributedTicket, Long> {
}
분산락을 적용하기 위해 어노테이션을 활용했다
RedissonLock
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface RedissonLock {
String value(); // Lock의 이름 (고유값)
long waitTime() default 50000L; // Lock획득을 시도하는 최대 시간 (ms)
long leaseTime() default 20000L; // 락을 획득한 후, 점유하는 최대 시간 (ms)
}
분산락이 필요한 메소드에 @RedissonLock을 붙이면 된다
RedissonLock이 붙은 메소드를 분산락으로 처리하기 위해 AOP를 활용한 Aspect를 구현해야 한다
RedissonLockAspect
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class RedissonLockAspect {
private final RedissonClient redissonClient;
private final AopForTransaction aopForTransaction;
@Around("@annotation(com.redisson.distributed.RedissonLock)")
public void redissonLock(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
RedissonLock annotation = method.getAnnotation(RedissonLock.class);
String lockKey = method.getName() + CustomSpringELParser.getDynamicValue(signature.getParameterNames(), joinPoint.getArgs(), annotation.value());
RLock lock = redissonClient.getLock(lockKey);
try {
boolean lockable = lock.tryLock(annotation.waitTime(), annotation.leaseTime(), TimeUnit.MILLISECONDS);
if (!lockable) {
log.info("Lock 획득 실패={}", lockKey);
return;
}
log.info("락 획득 및 로직 수행");
aopForTransaction.proceed(joinPoint);
} catch (InterruptedException e) {
log.info("에러 발생");
throw e;
} finally {
log.info("락 해제");
lock.unlock();
}
}
}
여기서 가장 중요한 부분은 AopForTransaction이다
AopForTransaction
@Component
public class AopForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Object proceed(final ProceedingJoinPoint joinPoint) throws Throwable {
return joinPoint.proceed();
}
}
왜 굳이 AopForTransaction을 만들어서 새로운 트랜잭션으로 감싸서 실행해줘야 할까?
그 이유는 락을 반납하기 전에 트랜잭션 커밋이 이루어져야 하기 때문이다
트랜잭션이 커밋되기 전에 락을 먼저 반납하면 발생하는 문제를 그림으로 확인해보자

분명 락을 사용하는 이유는 누군가 공유 자원을 수정하기 전에 데이터를 읽지 못하기 위함이다.
하지만 위 경우에는 락을 적용했는데도 불구하고 유저 B가 Old data를 조회하는 문제가 발생한다
따라서 AOP를 통한 락 획득-반납 과정 사이에 AopForTransaction을 통해 트랜잭션이 생성-커밋 되게 만들었다
CustomSpringELParset는 전달받은 락 이름을 보다 자유롭게 적용하기 위함이다
CustomSpringELParset
public class CustomSpringELParser {
public static Object getDynamicValue(String[] parameterNames, Object[] args, String key) {
SpelExpressionParser parser = new SpelExpressionParser();
StandardEvaluationContext context = new StandardEvaluationContext();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return parser.parseExpression(key).getValue(context, Object.class);
}
}
이제 위 분산락을 사용하기 위한 서비스 코드를 만들어보자
DistributedTicketService
@Service
@RequiredArgsConstructor
public class DistributedTicketService {
private final DistributedTicketRepository distributedTicketRepository;
@RedissonLock(value = "#ticketId")
public void ticketingWithRedisson(Long ticketId, Long quantity) {
DistributedTicket distributedTicket = distributedTicketRepository.findById(ticketId).orElseThrow();
distributedTicket.decrease(quantity);
distributedTicketRepository.saveAndFlush(distributedTicket);
}
}
여기서 중요한 점은 습관처럼 class레벨과, @RedissonLock이 적용된 메소드에 @Transactional을 붙이면 안 된다는 것이다.
RedissonLockAspect + AopForTransaction을 통해 락 획득-반납 사이에 트랜잭션이 생성-커밋까지 모두 이루어진다.
service 단에서 @Transactional을 감싸버리면 트랜잭션이 커밋되기 전에 락을 반납 하게 된다.
여기까지 분산락 적용이 마무리되었고, 테스트까지 진행해보자
DistributedTicketServiceTest
@Slf4j
@SpringBootTest
class DistributedTicketServiceTest {
@Autowired
private DistributedTicketService distributedTicketService;
@Autowired
private DistributedTicketRepository distributedTicketRepository;
private final static Integer CONCURRENT_COUNT = 100;
private static Long TICKET_ID = null;
private final static StopWatch stopwatch = new StopWatch();
@BeforeEach
public void before() {
log.info("1000개의 티켓 생성");
DistributedTicket distributedTicket = new DistributedTicket(1000L);
DistributedTicket saved = distributedTicketRepository.saveAndFlush(distributedTicket);
TICKET_ID = saved.getId();
}
@AfterEach
public void after() {
distributedTicketRepository.deleteAll();
}
private void ticketingTest(Consumer<Void> action) throws InterruptedException {
Long originQuantity = distributedTicketRepository.findById(TICKET_ID).orElseThrow().getQuantity();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.submit(() -> {
try {
action.accept(null);
} finally {
latch.countDown();
}
});
}
latch.await();
DistributedTicket distributedTicket = distributedTicketRepository.findById(TICKET_ID).orElseThrow();
assertEquals(originQuantity - CONCURRENT_COUNT, distributedTicket.getQuantity());
}
@Test
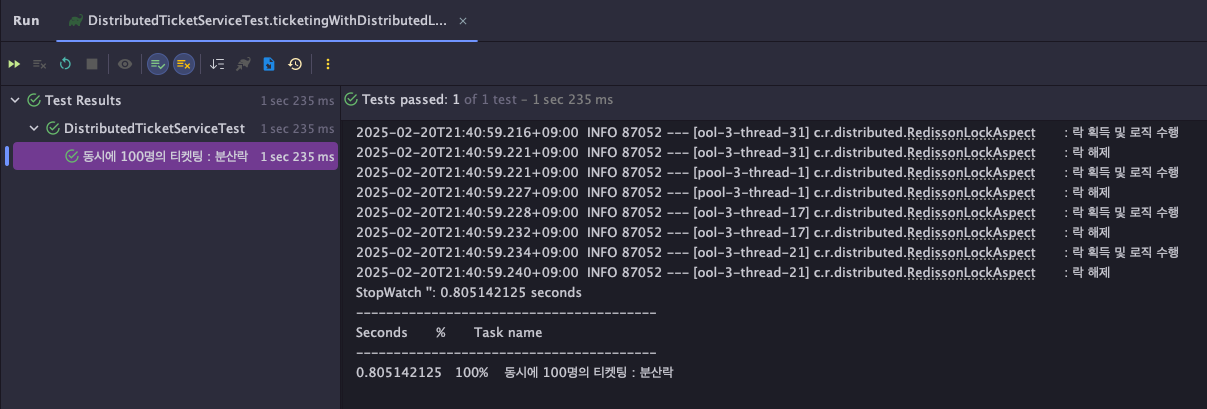
@DisplayName("동시에 100명의 티켓팅 : 분산락")
public void ticketingWithDistributedLock() throws Exception {
stopwatch.start("동시에 100명의 티켓팅 : 분산락");
ticketingTest((_no) -> distributedTicketService.ticketingWithRedisson(TICKET_ID, 1L));
stopwatch.stop();
System.out.println(stopwatch.prettyPrint());
}
}
serviceTest 코드도 마찬가지로 롤백한다고 클래스 단에 @Transactional을 붙이면 커밋 전에 락이 반납되므로 주의하자
테스트 결과
7. 개선점
1. 적용 여부 확인의 어려움
redisson을 마킹 어노테이션 + AOP 기능을 활용하여 처리하면서 key값을 리터럴로 관리해야 한다.
이러한 까다로운 key 파라미터를 그나마 편리하기 사용하기 위해 EL Parser(Expression Language Parser)를 구현하였다.
하지만 문자열 리터럴을 그대로 사용하는 문제는 변함없이 존재하기 때문에 잘못 작성하더라도 컴파일 시점에 에러를 발견하지 못한다
2. 락 장시간 점유로 인한 성능 저하 우려
지금 개발한 기능은 정확히 락이 필요한 메소드 실행 시간동안만 락을 점유 하지 않는다.
그 락이 필요한 메소드를 포함하고 있는 서비스 단의 메소드에 @RedissonLock을 통해 서비스 메소드가 종료되어야 락이 반납된다
서비스 메소드에서 락 필요 영역 : 3초 / 락 불필요 영역 : 1초라고 가정해보자.
이 서비스 메소드가 3번 호출 됐을 때, 현재 코드로는 4 * 3 = 12초가 소요된다.
만약 락이 필요한 영역만 락을 적용한다면 4 + 1 + 1 = 6초가 된다.
이를 개선한 코드는 다음 게시글에서 작성해보겠다
'Project' 카테고리의 다른 글
| 함수형 프로그래밍을 적용한 분산락 성능 개선 (2) (0) | 2025.02.21 |
|---|---|
| Lambda + CDN을 통한 스트리밍 영상 제공 (1) | 2025.02.19 |
| GitHub Actions + ECR + ECS + ALB를 통한 CICD (1) | 2024.12.28 |