함수형 프로그래밍을 적용한 분산락 성능 개선 (2)
이전 글과 이어지는 게시글입니다
1. 개요
이전글에서는 분산락에 개선점을 언급하였고, 이를 해결하기 위해 함수형 프로그래밍을 도입한 과정을 소개하려고 한다.
분산락에 개선점
- 적용 여부 확인의 어려움
- 락 장시간 점유로 인한 성능 저하
이를 개선하기 위해선 먼저 key 관리 방법을 바꾸고, 락이 필요한 영역에만 락을 적용해야 한다.
기존 코드를 함수형 프로그래밍으로 개선하여 해결할 수 있다.
함수형 프로그래밍은 간단히 파라미터로 함수를 넘기는 것을 말한다.
2. 구현
LockManager
@Slf4j
@RequiredArgsConstructor
@Component
public class LockManager {
private final RedissonClient redissonClient;
private final SupplierForTransaction supplierForTransaction;
private final String PREFIX = "RedissonLock-";
public <T> T lock(String lockKey, Supplier<T> supplier) {
RLock lock = redissonClient.getLock(PREFIX + lockKey);
try {
boolean lockable = lock.tryLock(50000, 20000, TimeUnit.MILLISECONDS);
if (!lockable) {
log.info("Lock 획득 실패={}", lockKey);
throw new RuntimeException("Lock 획득 실패");
}
log.info("락 획득 및 로직 수행");
return supplierForTransaction.get(supplier);
} catch (InterruptedException e) {
log.error("락을 획득하는 중 에러 발생", e);
Thread.currentThread().interrupt();
} finally {
if (lock.isHeldByCurrentThread()) {
log.info("락 해제");
lock.unlock();
}
}
throw new RuntimeException("Lock 획득 실패");
}
}
SupplierForTransaction
@Component
public class SupplierForTransaction {
@Transactional(propagation = Propagation.REQUIRES_NEW)
public <T> T proceed(Supplier<T> supplier) {
return supplier.get();
}
}
위 코드를 통해 락이 필요한 부분만 Supplier로 넘겨주면 된다.
기존 코드는 Aspect를 통해 JoinPoint를 받아 이를 트랜잭션으로 감싸줬다면, 이젠 함수를 받아서 트랜잭션을 감싸야 하기 때문에 AopForTransaction 대신 SupplierForTransaction을 통해 처리하였다.
DistributedTicketServiceV2
@Service
@RequiredArgsConstructor
public class DistributedTicketServiceV2 {
private final LockManager lockManager;
private final DistributedTicketRepository distributedTicketRepository;
public void ticketingWithRedisson(Long ticketId, Long quantity) {
sleep(500);
lockManager.lock(
String.valueOf(ticketId),
() -> {
ticketing(ticketId, quantity);
return null;
});
}
private void ticketing(Long ticketId, Long quantity) {
DistributedTicket distributedTicket = distributedTicketRepository.findById(ticketId).orElseThrow();
distributedTicket.decrease(quantity);
distributedTicketRepository.saveAndFlush(distributedTicket);
}
}
Supplier는 반환값이 필요하지만 ticketing은 void형태로 반환값을 null로 하여 파라미터에 넣어줘야 했다.
AOP가 아니라 함수형 프로그래밍을 직접 실행시켜야 하기 때문에 전보단 약간 복잡해졌다.
sleep(500)은 개선하기 전 코드와 비교하기 위해 추가했다.
여기까지 함수형 프로그래밍이 적용된 개선된 코드이다.
이제 테스트를 해보자
3. 테스트
테스트를 하기 위해 이전 코드에도 sleep(500)을 추가해두자
DistributedTicketServiceV1 (기존 이름은 DistributedTicketService)
public class DistributedTicketServiceV1 {
...
@RedissonLock(value = "#ticketId")
public void ticketingWithRedisson(Long ticketId, Long quantity) {
// 추가
sleep(500);
DistributedTicket distributedTicket = distributedTicketRepository.findById(ticketId).orElseThrow();
distributedTicket.decrease(quantity);
distributedTicketRepository.saveAndFlush(distributedTicket);
}
}
개선된 코드 테스트도 개선 전 테스트 코드와 다를 바 없다
DistributedTicketServiceV2Test
@Slf4j
@SpringBootTest
class DistributedTicketServiceV2Test {
@Autowired
private DistributedTicketServiceV2 distributedTicketServiceV2;
@Autowired
private DistributedTicketRepository distributedTicketRepository;
private final static Integer CONCURRENT_COUNT = 100;
private static Long TICKET_ID = null;
private final static StopWatch stopwatch = new StopWatch();
@BeforeEach
public void before() {
log.info("1000개의 티켓 생성");
DistributedTicket distributedTicket = new DistributedTicket(1000L);
DistributedTicket saved = distributedTicketRepository.saveAndFlush(distributedTicket);
TICKET_ID = saved.getId();
}
@AfterEach
public void after() {
distributedTicketRepository.deleteAll();
}
private void ticketingTest(Consumer<Void> action) throws InterruptedException {
Long originQuantity = distributedTicketRepository.findById(TICKET_ID).orElseThrow().getQuantity();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(CONCURRENT_COUNT);
for (int i = 0; i < CONCURRENT_COUNT; i++) {
executorService.submit(() -> {
try {
action.accept(null);
} finally {
latch.countDown();
}
});
}
latch.await();
DistributedTicket distributedTicket = distributedTicketRepository.findById(TICKET_ID).orElseThrow();
assertEquals(originQuantity - CONCURRENT_COUNT, distributedTicket.getQuantity());
}
@Test
@DisplayName("동시에 100명의 티켓팅 : 분산락 - 함수형 프로그래밍")
public void ticketingWithDistributedLock() throws Exception {
stopwatch.start("동시에 100명의 티켓팅 : 분산락 - 함수형 프로그래밍");
ticketingTest((_no) -> distributedTicketServiceV2.ticketingWithRedisson(TICKET_ID, 1L));
stopwatch.stop();
System.out.println(stopwatch.prettyPrint());
}
}
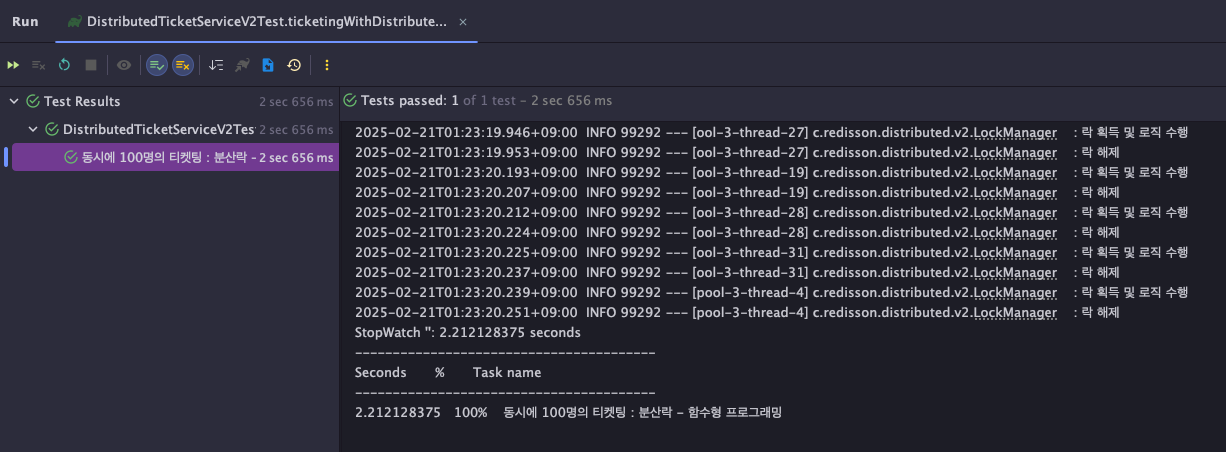
함수형 프로그래밍이 적용 - 개선된 코드 테스트 결과
개선 전 테스트 결과

테스트 결과 분석
테스트 설명
- Ticket의 quantity(수량)은 1000개 할당
- 100개의 요청을 32개의 스레드로 처리
- 하나의 요청은 생성한 티켓에서 수량을 1개 감소하도록 적용
- 이 요청에는 락이 불필요한 영역(sleep(500):0.5초)과 락이 필요한 영역(티켓 개수 감수)이 포함되어있다
개선 전 코드는 52.8초 vs 개선 후 코드는 2.8초라는 결과에 집중하자
개선된 코드는 락이 필요한 영역만 락을 할당해줬기 때문에 약 100개의 요청마다 0.5초를 아꼈다.
즉, 개선 전 후의 차이인 50초는 100 * 0.5 = 50의 결과이다.
이를 통해 락이 필요한 영역에만 락을 할당해주었기 때문에 락이 불필요한 영역을 로직은 락을 기다리지 않고 먼저 실행될 수 있었고 50초라는 시간의 이점을 얻을 수 있었다.